The data life cycle¶
The life cycle of a single-cell count matrix often looks as follows:
Generation from primary read data in a read alignment pipeline.
Annotation with cell types and sample meta data.
Publication of annotated data, often together with a manuscript.
Curation of this public data set for the purpose of a meta study. In a python workflow, this curation step could be a scanpy script based on data from step 3, for example.
Usage of data curated specifically for the use case at hand, for example for a targeted analysis or a training of a machine learning model.
where step 1-3 is often only performed once by the original authors of the data set, while step 4 and 5 are repeated multiple times in the community for different meta studies. Sfaira offers the following functionality groups that accelerate steps along this pipeline:
Sfaira tools across life cycle¶
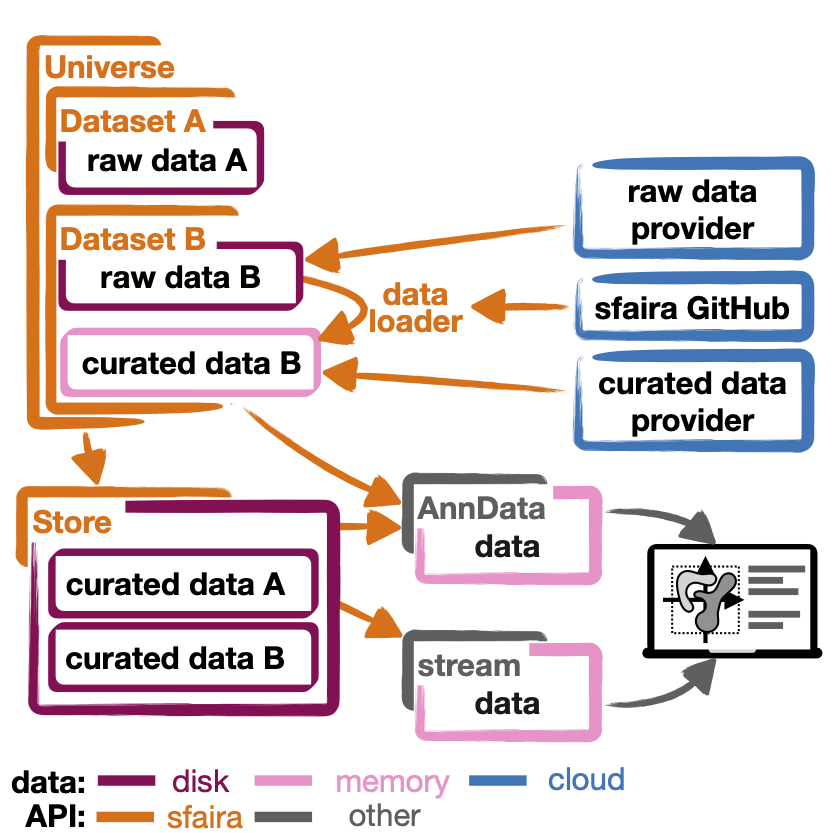
I) Data loaders¶
We maintain streamlined data loader code that improve Curation (step 4) and make this step sharable and iteratively improvable. Read more in our guide to data contribution Writing data loaders.
II) Dataset, DatasetGroup, DatasetSuperGroup¶
Using the data loaders from (I), we built an interface that can flexibly download, subset and curate data sets from the sfaira data zoo, thus improving Usage (step 5). This interface can yield adata instances to be used in a scanpy pipeline, for example. Read more in our guide to data consumption Using data loaders.
III) Stores¶
Using the streamlined data set collections from (II), we built a computationally efficient data interface for machine learning on such large distributed data set collection, thus improving Usage (step 5): Specifically, this interface is optimised for out-of-core observation-centric indexing in scenarios that are typical to machine learning on single-cell data. Read more in our guide to data stores Data stores.
FAIR data¶
FAIR data is a set of data management guidelines that are designed to improve data reuse and automated access (see also the original publication of FAIR for more details). The key data management topics addressed by FAIR are findability, accessibility, interoperability and reusability. Single-cell data sets are usually public and also adhere to varying degrees to FAIR principles. We designed sfaira so that it improves FAIR attributes of published data sets beyond their state at publication. Specifically, sfaira:
improves findability of data sets by serving data sets through complex meta data query.
improves accessibility of data sets by serving streamlined data sets.
improves interoperability of data sets by streamlining data using versioned meta data ontologies.
improves reusability of data sets by allowing for iterative improvements of meta data annotation and by shipping usage critical meta data.